Few days ago in my previous articles I had discussed about the advanced file formats like Parquet and ORC and the performance improvement in the hadoop ecosystem. We had also seen the improvements of Parquet format. Today I would like to explore more on the ORC compression format and how it is compatible with Hive and Spark SQL.
Again, I am going to use the same data set (NYC taxi) and create the ORC_NYCTAXI table so that I can compare with the TXT_NYCTAXI.
I am going to use SparkSQL to create the ORC_NYCTAXI table, just to show to we can integrate the SparkSQL with Hive/Hcatalog
Initiate the spark program with an hive context as shown below
import org.apache.spark.sql.hive.orc._
import org.apache.spark.sql._
val hiveC = new org.apache.spark.sql.hive.HiveContext(sc)
create the ORC format table
hiveC.sql("create table ORC_NYCTAXI stored as orc as select * from TXT_NYCTAXI")

Let us see how we can easily access ORC format data files from HDFS without any Hive Catalog from SparkSQL.
import org.apache.spark.sql.hive.orc._
import org.apache.spark.sql._
val hiveC = new org.apache.spark.sql.hive.HiveContext(sc)
val load_orcnyc = hiveC.orcFile("/apps/hive/warehouse/orc_nyctaxi")
load_orcnyc.registerTempTable("ORCNycTaxi")
hiveC.sql("select * from ORCNycTaxi").take(5).foreach(println)


This shows how easy and flexible in reading the data in ORC format , where one has no need to remember the schema definition and can still work on the data with very few lines of code using Spark SQL.
Now, let us examine the storage
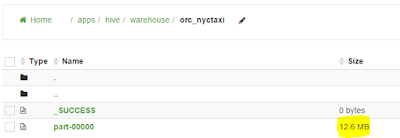
The compression is about 17%-18% of the orginal size. Where as we had seen that Parquet format is about 30% of the original size. So ORC has better compression ratio than Parquet format.
Now Let us see the query performance

It has been observed that both the Parquet and ORC are the same in read performance using Spark SQL, where ORC has better compression in storage. It depends on how you are querying the data. If you are using Hive and SparkSQL ORC is better or the same as Parquet. If you are using Impala, Parquet gives better read performance.
Hope this interests you . See you next time with another interesting topic.
Again, I am going to use the same data set (NYC taxi) and create the ORC_NYCTAXI table so that I can compare with the TXT_NYCTAXI.
I am going to use SparkSQL to create the ORC_NYCTAXI table, just to show to we can integrate the SparkSQL with Hive/Hcatalog
Initiate the spark program with an hive context as shown below
import org.apache.spark.sql.hive.orc._
import org.apache.spark.sql._
val hiveC = new org.apache.spark.sql.hive.HiveContext(sc)
create the ORC format table
hiveC.sql("create table ORC_NYCTAXI stored as orc as select * from TXT_NYCTAXI")

Let us see how we can easily access ORC format data files from HDFS without any Hive Catalog from SparkSQL.
import org.apache.spark.sql.hive.orc._
import org.apache.spark.sql._
val hiveC = new org.apache.spark.sql.hive.HiveContext(sc)
val load_orcnyc = hiveC.orcFile("/apps/hive/warehouse/orc_nyctaxi")
load_orcnyc.registerTempTable("ORCNycTaxi")
hiveC.sql("select * from ORCNycTaxi").take(5).foreach(println)

This shows how easy and flexible in reading the data in ORC format , where one has no need to remember the schema definition and can still work on the data with very few lines of code using Spark SQL.
Now, let us examine the storage
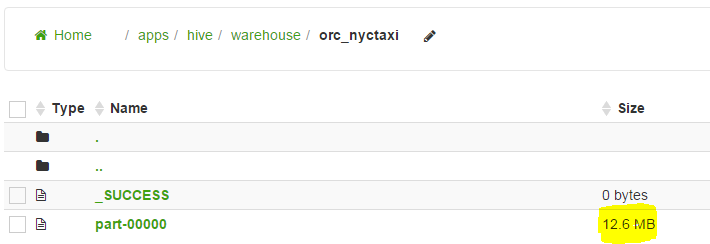
The compression is about 17%-18% of the orginal size. Where as we had seen that Parquet format is about 30% of the original size. So ORC has better compression ratio than Parquet format.
Now Let us see the query performance

It has been observed that both the Parquet and ORC are the same in read performance using Spark SQL, where ORC has better compression in storage. It depends on how you are querying the data. If you are using Hive and SparkSQL ORC is better or the same as Parquet. If you are using Impala, Parquet gives better read performance.
Hope this interests you . See you next time with another interesting topic.